Как не запускать тест A / B
Оригинальная статья: How Not To Run an A/B Test
Автор статьи: Evan Miller
Источник: http://www.evanmiller.org/how-not-to-run-an-ab-test.html
18 апреля 2010 г.
Если вы проводите тесты A / B на своем веб-сайте и регулярно проверяете текущие эксперименты для получения значительных результатов, вы можете стать жертвой того, что статистики называют повторными ошибками тестирования значимости. В результате, хотя ваша панель инструментов говорит, что результат статистически значим, есть хороший шанс, что это на самом деле незначительно. В этой заметке объясняется, почему.
Происхождение
Когда контрольная панель A / B говорит, что существует «95% -ный шанс на избиение оригинала» или «вероятность статистической значимости на 90%», он задает следующий вопрос: считая, что между A и B нет основной разницы, как часто мы будем увидеть случайную разницу, как в данных? Ответ на этот вопрос называется уровнем значимости, а «статистически значимые результаты» означают, что уровень значимости низкий, например, 5% или 1%. Панели обычно используют дополнение (например, 95% или 99%) и сообщают об этом как о «шансе на избиение оригинала» или что-то в этом роде.
Однако расчет значимости делает критическое предположение, что вы, вероятно, нарушили, даже не осознав этого: размер выборки был зафиксирован заранее . Если вместо того, чтобы заранее решить, «этот эксперимент соберет ровно 1000 наблюдений, - говорите вы, - мы запустим его, пока не увидим существенную разницу», все уровни значимых значений становятся бессмысленными . Этот результат абсолютно противоречив, и все пакеты тестирования A / B там игнорируют его, но я попытаюсь объяснить источник проблемы простым примером.
Пример
Предположим, вы проанализировали эксперимент после 200 и 500 наблюдений.Есть четыре вещи, которые могут произойти:
| Сценарий 1 | Сценарий 2 | Сценарий 3 | Сценарий 4 | |
|---|---|---|---|---|
| После 200 наблюдений | Незначительный | Незначительный | Значительное! | Значительное! |
| После 500 наблюдений | Незначительный | Значительное! | Незначительный | Значительное! |
| Конец эксперимента | Незначительный | Значительное! | Незначительный | Значительное! |
Предполагая, что лечение A и B одинаково, а уровень значимости составляет 5%, то в конце эксперимента мы получим значительный результат в 5% случаев.
Но предположим, что мы прекратили эксперимент, как только получится значительный результат. Теперь рассмотрим четыре вещи, которые могут произойти:
| Сценарий 1 | Сценарий 2 | Сценарий 3 | Сценарий 4 | |
|---|---|---|---|---|
| После 200 наблюдений | Незначительный | Незначительный | Значительное! | Значительное! |
| После 500 наблюдений | Незначительный | Значительное! | испытание прекратилось | испытание прекратилось |
| Конец эксперимента | Незначительный | Значительное! | Значительное! | Значительное! |
Первая строка такая же, как и раньше, и уровни значимости после 200 наблюдений прекрасно соблюдены. Но теперь посмотрим на третий ряд. В конце эксперимента, предполагая, что A и B на самом деле одинаковы, мы увеличили отношение значительных относительно незначительных результатов. Следовательно, уровень значимости - «процент времени, когда наблюдаемая разница обусловлена случайностью» - будет неправильным.
Насколько велика проблема?
Предположим, что ваш коэффициент конверсии составляет 50%, и вы хотите проверить, показывает ли новый логотип коэффициент конверсии более 50% (или меньше). Вы прекращаете эксперимент, как только это имеет значение 5%, или вы вызываете эксперимент после 150 наблюдений. Теперь предположим, что ваш новый логотип фактически ничего не делает. Какой процент времени ваш эксперимент ошибочно найдет значительный результат? Не более пяти процентов, не так ли? Может быть, шесть процентов, в свете предыдущего анализа?
Попробуйте 26,1% - более чем в пять раз больше, чем вы считали уровнем значимости . Это своего рода наихудший сценарий, так как мы проводим тест значимости после каждого наблюдения, но это неслыханно. По крайней мере одна структура тестирования A / B на самом деле предоставляет код для автоматической остановки экспериментов после значительного результата. Это звучит как опрятный трюк, пока вы не осознаете, что это статистическая мерзость.
Повторное тестирование значения всегда увеличивает скорость ложных срабатываний, т. Е. Вы думаете, что многие незначительные результаты значительны (но не наоборот). Проблема будет присутствовать, если вы когда-нибудь окажетесь «заглядывая» в данные и прекратите эксперимент, который, кажется, дает значительный результат. Чем больше вы заглядываете, тем больше ваши уровни значимости будут отключены. Например, если вы заглядываете в постоянный эксперимент десять раз, то то, что вы считаете значимым на 1%, на самом деле составляет всего 5%. Ниже приведены другие значения значимости, которые нужно увидеть, чтобы получить фактическое значение 5%:
| Вы заглянули ... | Чтобы получить 5% фактическое значение, которое вам нужно ... |
|---|---|
| 1 раз | 2,9% сообщили о значимости |
| 2 раза | 2,2% сообщили о значимости |
| три раза | 1,8% сообщили о значимости |
| 5 раз | 1,4% сообщили о значимости |
| 10 раз | 1,0% сообщили о значимости |
Определите, какая у вас проблема, но если вы управляете своим бизнесом, постоянно проверяя результаты текущих тестов A / B и принимаете быстрые решения, тогда эта таблица должна дать вам мурашки по коже.
Что можно сделать?
Если вы запускаете эксперименты: лучший способ избежать повторных ошибок тестирования значимости - неоднократно не тестировать значение. Определите размер выборки заранее и подождите, пока эксперимент не закончится, прежде чем вы начнете полагать, что «шанс изгнать оригинальные» цифры, которые дает вам программное обеспечение для тестирования A / B. «Peeking» по данным в порядке, пока вы можете сдерживать себя от остановки эксперимента до того, как он начнет свой курс. Я знаю, что это противоречит природе человека, поэтому, возможно, лучший совет: не заглядывать!
Поскольку вы собираетесь исправить размер выборки заранее, какой размер выборки вы должны использовать? Эта формула является хорошим правилом:
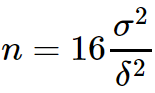
Где δ - минимальный эффект, который вы хотите обнаружить, и σ2 - это дисперсия выборки, которую вы ожидаете. Конечно, вы можете не знать разницу, но если это всего лишь биномиальная пропорция, которую вы вычисляете (например, процентный коэффициент конверсии), то дисперсия определяется:
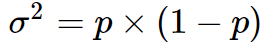
Согласование с размером выборки полностью смягчает описанную здесь проблему.
ОБНОВЛЕНИЕ, май 2013: вы можете увидеть эту формулу в действии с помощью моего нового интерактивного калькулятора размера выборки . Введите размер эффекта, который вы хотите обнаружить, установите уровни мощности и значимости, и вы получите легко читаемый номер, в котором указывается нужный размер выборки. КОНЕЦ ОБНОВЛЕНИЯ
Если вы пишете программное обеспечение для тестирования A / B: не сообщайте уровни значимости до окончания эксперимента и не используйте уровни значимости, чтобы решить, должен ли эксперимент останавливаться или продолжаться. Вместо того, чтобы сообщать о значимости текущих экспериментов, сообщите, как можно получить большой эффект, учитывая текущий размер выборки. Это можно рассчитать с помощью:
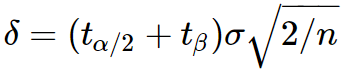
Где два t t-статистика для заданного уровня значимости α/2 и мощности (1−β).
Как ни звучит, вы можете даже исключить «текущую оценку» эффекта лечения до окончания эксперимента. Если эта информация используется для прекращения экспериментов, то ваши уровни значимости - это мусор.
Если вы действительно хотите сделать это правильно: исправление размера выборки может быть разочаровывающим. Что делать, если ваши изменения являются безудержным ударом, не следует ли сразу его развернуть? Эта проблема преследовала медицинский мир в течение длительного времени, поскольку медицинские исследователи часто хотят прекратить клинические испытания, как только новое лечение выглядит эффективным, но им также необходимо сделать достоверные статистические выводы по их данным. Вот несколько подходов, используемых в разработке медицинских экспериментов, которые кто-то действительно должен адаптировать к сети:
-
Последовательный дизайн эксперимента : последовательный эксперимент позволяет заранее настроить контрольные точки, где вы решите, продолжать эксперимент или нет, и дает вам правильные уровни значимости.
-
Байесовский эксперимент : с байесовским экспериментом вы можете в любой момент остановить эксперимент и сделать совершенно правильные выводы. Учитывая характер веб-экспериментов в реальном времени, байесовский дизайн выглядит как путь вперед.
Подробнее: «Байесовское тестирование A / B»
Заключение
Несмотря на то, что они кажутся мощными и удобными, представления на панели мониторинга текущих экспериментов A / B предполагают неправильное использование. В любое время, когда они используются в сочетании с ручным или автоматическим «правилом остановки», полученные тесты значимости просто недействительны. До тех пор, пока в программном обеспечении не будут реализованы последовательные или байесовские эксперименты, каждый, кто работает в веб-экспериментах, должен проводить эксперименты, в которых размер выборки был исправлен заранее, и придерживаться этого размера выборки с почти религиозной дисциплиной.